[AnswerDev] 5. 동적 페이지 크롤링 using Selenium

이제 웬만한 환경 설정은 완료했고, Studocu 사이트에서 답지를 크롤링해서 내 페이지에 띄우면 된다.
사실 다른 기능들은 별로 필요가 없기 때문에 이 기능만 구현되면 이 프로젝트는 그냥 끝이다...
물론 다른 부가적인 기능들을 넣으려면 넣을 수는 있겠지만, 큰 필요는 없을 것 같아서 그냥 핵심 기능(크롤링 후 띄우기)만 구현하기로 했다.
우선 이 글을 쓰는 2024. 09. 11. 현재 Selenium의 최신 버전은 4.24.0버전으로, 크롬 드라이버를 사용할 경우 크롬 v128버전까지 지원한다.
마침 내가 사용하는 크롬 버전이 v128으로 가장 최신 버전이었기에, 나는 Selenium 4.24.0을 바로 build.gradle에 추가해 주었다.
// build.gradle
implementation group: 'org.seleniumhq.selenium', name: 'selenium-java', version: '4.24.0'
그리고 이제 이 Selenium 라이브러리를 활용하여 특정 사이트의 HTML을 크롤링할 수 있게 되었다.
그럼 Selenium을 어떻게 사용해야 하는지 천천히 알아보자.
먼저 나는 크롬 브라우저를 활용하여 크롤링을 하려고 했었다.
그러나 배포하려는 EC2 Ubuntu 환경에서는 크롬 브라우저 호환성 이슈 때문에, 크롬 브라우저를 포크해서 만든 커스텀 브라우저인 크로미움(Chromium) 브라우저를 설치하여 사용하기로 했다.
이러한 상황 속에서, Selenium의 초기 설정은 다음과 같이 하면 된다.
// AnswerService.java
@Async
@Transactional
public CompletableFuture<RegisterAnswerServerDto> registerAnswer(RegisterAnswerClientDto dto) throws IOException {
ChromeOptions options = new ChromeOptions();
System.setProperty("webdriver.chrome.driver", "/usr/bin/chromedriver"); // Ubuntu 환경의 경우
options.setBinary("/usr/bin/chromium-browser"); // chrome이 아니라 chromium 브라우저의 경우
options.addArguments("headless");
options.addArguments("disable-dev-shm-usage");
options.addArguments("disable-gpu");
options.addArguments("no-sandbox");
options.addArguments("disable-blink-features=AutomationControlled");
options.setExperimentalOption("excludeSwitches", new String[]{"enable-automation"});
options.setExperimentalOption("useAutomationExtension", false);
options.addArguments("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36");
options.addArguments("lang=ko_KR");
options.addArguments("window-size=1920x1080");
options.addArguments("ignore-certificate-errors");
WebDriver driver = new ChromeDriver(options);
...- System.setProperty(...) : Ubuntu 환경에서 크롬 드라이버를 직접 설치했을 경우, 그 크롬 드라이버의 경로를 지정해 주는 역할을 한다.
- options.setBinary(..) : 설치한 chromium 브라우저의 경로를 적어준다.
- options.addArguments("headless") : Ubuntu 환경에서는 크롬 브라우저를 띄울 수 없기 때문에 headless로 동작시켜 줌으로써 브라우저를 띄우지 않고도 크롤링할 수 있게 해주는 옵션.
- 나머지 options.addArguments(...) : headless로 크롤링을 시도할 경우 사이트의 봇 탐지에 걸릴 수 있기 때문에, 마치 진짜 사용자인 척 위장하는 옵션들.
이렇게 해주면 Selenium으로 크롤링하기 위한 초기 설정이 끝난다.
이렇게 선언한 WebDriver의 findElement 메서드를 통해 특정 사이트의 HTML 요소를 가져올 수 있다.
나는 By.cssSelector()을 사용해서 가져오려는 요소의 쿼리셀렉터를 통해 Studocu의 답지 이미지와 이미지의 총 개수를 가져왔다.
자세한 내용은 해당 사이트의 보안을 그대로 누설하는 것이기에 생략하도록 하겠다.
// querySelector을 통해 해답 이미지의 총 개수를 가져옴
int maxPageNumber = Integer.parseInt(driver.findElement(By.cssSelector("span[data-test-selector=\"total-document-available-pages\"]")).getText());
이렇게 해서 답지 이미지들의 url들을 모두 가져온 후, 이를 그대로 내 인덱스 페이지에 띄운다.
완성된 페이지의 이미지는 다음과 같다.
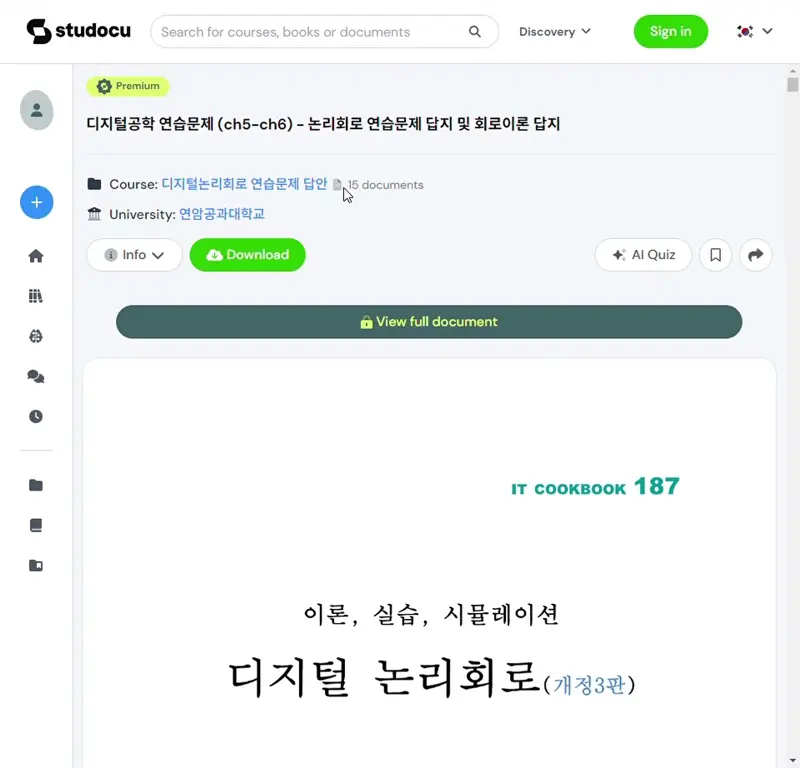
이렇게 AnswerDev완성~